


2024年2月24日更新
用ThreadPoolExecutor代替了multiprocessing pool,增加了ts分段下载错误的重试(10次),这样可以避免评论中提到的
Exception in Tkinter callback
Traceback (most recent call last):
File "C:\Program Files\Python36\lib\tkinter\__init__.py", line 1699, in __call__
return self.func(*args)
File "D:\SealGod\Desktop\gui91.py", line 85, in start_download
p.map(downloader,ts_list)
File "C:\Program Files\Python36\lib\multiprocessing\pool.py", line 266, in map
return self._map_async(func, iterable, mapstar, chunksize).get()
File "C:\Program Files\Python36\lib\multiprocessing\pool.py", line 644, in get
raise self._value
multiprocessing.pool.MaybeEncodingError: Error sending result: '<multiprocessing.pool.ExceptionWithTraceback object at 0x000002197FE004E0>'. Reason: 'TypeError("cannot serialize '_io.BufferedReader' object",)'
的问题。
代码已更新。
前言
和之前的写的基本上一样,只不过加入了GUI界面,甚至还阉割了一点功能……比如
- 取消了进度条
不知道是不是我这个电脑太垃圾了,我点击下载之后就会卡死,下载完了才会跳出进度条 - 取消了打包成exe的文件
打包完实在是太大了。尽管我已经是在虚拟环境中打包的了,但软件体积仍然能臃肿到有到37M。
使用教程
1 确保所需要的软件包已经安装
你需要安装:
- python3
- requests
- bs4
- lxml
- pillow
- easygui
2 运行这个Python文件
在命令行(cmd)输入“python+你的文件地址”来运行,比如
python C:\Users\rvw\Desktop\gui91.py

3 在视频地址的输入框中填入视频的viewkey
这个viewkey在91视频的地址栏中可以看到。我这个程序自带了一个viewkey做示范,把它替换掉即可,然后点击解析
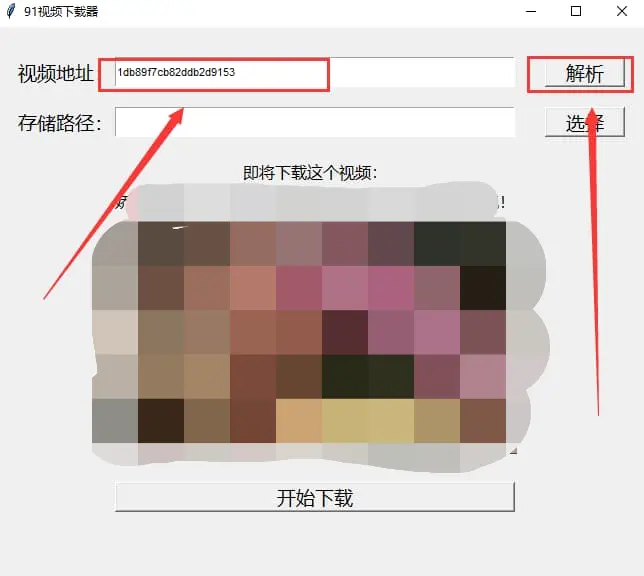
4 点击“选择”按钮选择下载路径
默认是在当前文件夹下以视频名称.mp4保存,你可以自定义

点击保存之后自动获取路径
5 点击开始下载
因为我没加进度条,你也不知道下载了没,所以我直接打开下载文件夹,手动看看进度吧

下载完成后会自动合并,然后提示你要不要打开文件夹

点击“是”,然后播放看看

应该是没问题
代码
import tkinter as tk
from tkinter import ttk
from easygui import filesavebox
import requests
from bs4 import BeautifulSoup
from PIL import ImageTk, Image
from io import BytesIO
from urllib.request import urlretrieve
# import multiprocessing as mp
import re, os
from concurrent import futures
title = 0
def parse_url():
global img
global title
global key
url = viewkey_entry.get()
key = url
detail_url = 'https://91porny.com/video/view/{}'.format(key)
r = requests.get(detail_url)
soup = BeautifulSoup(r.text, 'lxml')
title = soup.h4.text
titlelab1 = tk.Label(window, text='即将下载这个视频:', font=('微软雅黑', 12))
titlelab1.place(x=120, y=130, width=400, height=30)
titlelab2 = tk.Label(window, text=title, font=('微软雅黑', 12))
titlelab2.place(x=120, y=160, width=400, height=30)
poster_url = soup.video.get("data-poster")
img = ImageTk.PhotoImage(Image.open(BytesIO(requests.get(poster_url).content)))
imagelab = tk.Label(window)
imagelab.place(x=120, y=200)
imagelab.configure(image=img)
download_button.place(x=120, y=455, width=400, height=30)
def get_save_path():
if title == 0:
tk.messagebox.showerror(title='没有检测到视频', message='错误!请先解析下载地址!')
return
save_path = filesavebox('请选择保存的路径',default='{}.mp4'.format(title))
save_path_entry.delete(0)
save_path_entry.insert(0,save_path)
def make_dir():
if os.path.exists('videos_91'):
os.system('rd /s /q videos_91')
os.mkdir('videos_91')
os.chdir('videos_91')
def get_ts_list(key):
url = 'https://91porny.com/video/embed/{}'.format(key)
r = requests.get(url)
soup = BeautifulSoup(r.text, 'lxml')
m3u8_url = soup.find('video').get('data-src')
m3u8 = '/'.join(m3u8_url.split('/')[:-1])
index = requests.get(m3u8_url).text
ts_list = re.findall('index.*?ts', index)
return [(m3u8, i) for i in ts_list]
def downloader(ts, retry = 10):
try:
ts_url = '{}/{}'.format(ts[0], ts[1])
r = urlretrieve(ts_url, ts[1])
return True
except:
while retry > 0 :
retry += -1
if downloader(ts, retry):
break
else:
continue
def rename_ts(path, ts_list):
rename_dict = {i[1]:'{}.ts'.format(ts_list.index(i)+1).zfill(8) for i in ts_list}
for r, ds, fs in os.walk(path):
for f in fs:
os.rename(f,rename_dict[f])
def merge_ts(path, title):
os.chdir('..')
cwd = os.getcwd()
cmd = 'copy /b videos_91\*.ts {}'.format(title)
os.system(cmd)
os.system('rd /s /q videos_91')
def start_download():
filename = save_path_entry.get()
if filename=='':
tk.messagebox.showerror(title='没有检测到下载地址', message='错误!请选择下载路径!')
return
path = os.path.dirname(filename)
os.chdir(path)
make_dir()
ts_list = get_ts_list(key)
os.startfile(os.path.join(path,'videos_91'))
# p = mp.Pool()
# p.map(downloader,ts_list)
with futures.ThreadPoolExecutor(5) as executor:
executor.map(downloader, ts_list)
path = os.getcwd()
rename_ts(path, ts_list)
merge_ts(path, filename)
if tk.messagebox.askyesno(title='下载已完成!', message='下载已完成,视频存储至:\n{}\n立即打开文件夹?'.format(filename)) == True:
os.startfile(os.path.dirname(filename))
if __name__ == '__main__':
window = tk.Tk()
window.geometry('650x550')
window.title('91视频下载器')
tk.Label(window, text='视频地址:', font=('微软雅黑', 14)).place(x=20, y=30)
tk.Label(window, text='存储路径:', font=('微软雅黑', 14)).place(x=20, y=80)
viewkey_entry = tk.Entry(window, font=('Arial', 8), textvariable=tk.StringVar(value='1db89f7cb82ddb2d9153'))
viewkey_entry.place(x=120,y=30,width=400,height=30)
viewkey_button = tk.Button(window,text='解析', font=('微软雅黑', 14),command=parse_url)
viewkey_button.place(x=550,y=30,width=80,height=30)
save_path_entry = tk.Entry(window, font=('Arial', 8))
save_path_entry.place(x=120,y=80,width=400,height=30)
save_path_button = tk.Button(window,text='选择', font=('微软雅黑', 14),command=get_save_path)
save_path_button.place(x=550,y=80,width=80,height=30)
download_button = tk.Button(window,text='开始下载', font=('微软雅黑', 14),command=start_download)
window.mainloop()
Comments | 2 条评论
大佬, 我还是下载失败欸, 就下的默认那个视频, 能不能帮忙看看为什么? 感谢
今天试了一下,竟然还能用,只是要翻墙。